LLM Research: Adaptive RAG for Conversational Systems
Recommended1 | Source2
Supplementary reading to the research paper
RAGate: A Gating Model
- RAGate models conversation context and relevant inputs to predict if a conversational system requires RAG for improved responses.
- Conclusion: Effective application of RAGate in RAG-based conversational systems identifies when to use appropriate RAG for high-quality responses with high generation confidence.
Validation of RAGate
- Experimentation: Extensive experiments on an annotated Task-Oriented Dialogue (TOD) system dataset, KETOD, which builds upon the SGD dataset with TOD spanning 16 domains such as Restaurant and Weather.
- Findings: Without the addition of external knowledge, system responses are more diverse and natural in the early stages of a conversation. This suggests that misusing external knowledge can lead to problematic system responses and a negative user experience.
Integrating Large Language Models into Conversational Systems
Definition
Integrating LLMs into conversational systems means using these large, pre-trained models to power the dialogue management, response generation, and overall interaction dynamics within chatbots, virtual assistants, or any system that interacts with users through natural language.
Capabilities of LLMs
- LLMs, like GPT (Generative Pre-trained Transformer) models, have been trained on vast amounts of text data, enabling them to:
- Understand context
- Generate coherent and contextually relevant responses
- Exhibit a degree of reasoning
Traditional Conversational Systems (Pre-LLMs)
- Rule-Based Systems:
- Operated on predefined rules and patterns.
- Limitations: Rigid, struggling with unexpected inputs or complex language structures; required extensive manual effort to maintain and update.
- Template-Based Responses:
- Used predefined response templates with slots to fill in with user-specific information.
- Limitations: Could not generate novel responses or handle conversations beyond the templates' scope.
- Dialogue Management with State Machines:
- Managed dialogue flows with each state representing a stage in the conversation.
- Limitations: Cumbersome and complex for more open-ended or dynamic conversations.
- Traditional Machine Learning Methods:
- Used models like Support Vector Machines (SVMs), Naive Bayes, or simple neural networks.
- Limitations: Limited in understanding and generating natural language; heavily relied on predefined rules or templates.
- Information Retrieval-Based Systems:
- Matched user inputs with a large database of pre-written responses or documents.
- Limitations: Effectiveness depended heavily on the database's quality and comprehensiveness; struggled with nuanced conversations.
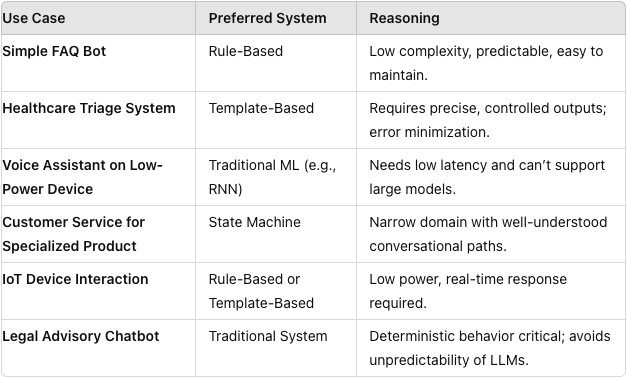
Advantages of Traditional Systems Over LLMs
- Cost Efficiency: Particularly for small businesses and startups.
- Simplicity and Efficiency: Ideal for simple FAQ bots.
- Deterministic Behavior: Crucial in areas where consequences of errors are significant, such as legal, healthcare, and finance.
- Limited Data Availability: Beneficial in niche or highly specialized domains.
- Lower Latency: Suitable for embedded systems or IoT devices.
- Lower Regulatory or Privacy Concerns: More manageable in regulated industries.
- Narrow, Well-Structured Domains: Effective where domain scope is limited and well-defined.
- Interoperability with Legacy Systems: Easier to integrate with existing infrastructure.
Example Use Cases for Traditional Systems
Retrieval-Augmented Generation (RAG) in Conversational Systems
Need for RAG
- Retrieval Component: The system retrieves relevant documents or information from a database or knowledge base based on the user's input.
- Generative Component: The generative model (like GPT) uses this retrieved information to generate a response, ensuring that the output is fluent, coherent, and grounded in specific, relevant knowledge.
- Assumption: There is an inherent need for a retrieval component to augment the generative capabilities of the model, particularly when the system is not explicitly controlled (i.e., the conversation is open-ended and not tightly scripted).
Case for Such Assumptions
- Knowledge Limitation: LLMs may not always have up-to-date or domain-specific knowledge, leading to the need for real-time retrieval from a dedicated database.
- Context Management: In multi-turn dialogues, retrieval can help manage context more effectively, pulling in relevant information that may have been mentioned earlier or is pertinent to the current query.
- Accuracy and Trustworthiness: RAG ensures that responses are more accurate, particularly in domains where factual correctness is critical.
Types of RAG Approaches:
Single-Pass RAG
- The system retrieves relevant documents or information in a single pass based on the input query. The retrieved content is directly used by the generative model to produce the output.
- Use Case: Common in question-answering systems or chatbots where a response is needed based on a single query.
Iterative RAG
- The system iteratively refines both the retrieval and generation processes. The initial retrieval generates a preliminary response, which is then used to refine the retrieval process.
- Use Case: Useful in complex, multi-turn conversations where context and user intent need to be refined through iterative interaction.
Knowledge-Enhanced RAG
- Integrates structured or semi-structured knowledge bases (e.g., knowledge graphs) into the retrieval process. This allows the generative model to use factual or relational knowledge more effectively.
- Use Case: Ideal for applications requiring high factual accuracy, such as medical or legal advice systems.
Hybrid RAG
- Combines retrieval from multiple sources, such as static corpora and real-time data, to enhance the generative output.
- Use Case: Suitable for real-time applications like customer support systems that need to draw on both historical data and live information.
Memory-Augmented RAG
- Uses a memory mechanism to store and retrieve past interactions or relevant data.
- Use Case: Effective in long-term conversational agents where maintaining context over multiple sessions is important.
Cross-Attention RAG
- An integrated approach where the generative model uses cross-attention mechanisms to directly attend to retrieved documents during the generation process.
- Use Case: Useful in tasks where the response must directly incorporate specific pieces of information from the retrieved content.
Modular RAG
- Breaks down the retrieval and generation tasks into distinct modules that can be independently optimized and then integrated.
- Use Case: Suitable for large-scale systems where different teams work on optimizing retrieval and generation separately.
Task-Specific RAG
- Customizes the RAG process for specific tasks by tailoring the retrieval component to the task at hand, such as retrieval-based summarization, dialogue systems, or knowledge-based QA.
- Use Case: Ideal for academic paper summarization or technical support where the task-specific nature of the content is crucial.
Efficiency Enhancement Methods
Dense Passage Retrieval Techniques
- Context: Particularly relevant in large-scale text retrieval for tasks like question answering or conversational systems.
- Approach: Unlike traditional retrieval methods that rely on sparse representations (e.g., TF-IDF or BM25), Dense Passage Retrieval (DPR) uses dense vector representations to capture semantic similarities between queries and documents.
Public Search Service for Effective Retrievers
-
Examples:
- Elasticsearch: A distributed search engine that allows for fast and scalable search operations over large datasets.
- Google Cloud Search API: A service that allows developers to implement search functionality within their applications, leveraging Google’s search technology.
- Purpose: These services enable developers to integrate advanced retrieval capabilities into their systems without needing to build the underlying infrastructure from scratch, providing optimized indexing, query processing, and ranking.
Task-Oriented Dialogue (TOD) Systems
- Definition: Aims to find the parameters of a model that maximize the likelihood of the observed data.
Subgraph Retrieval-Augmented Generation (SURGE)
- SURGE: Incorporates contrastive learning to optimize the latent representation space, ensuring that generated texts closely resemble the retrieved subgraphs.